100x Faster Clustering with Lilac Garden#
Jan 30, 2024
Automatic and human-readable clustering of 1 million conversations from Chatbot Arena, computed in 20 minutes.
Explore clusters and join the waitlist for Lilac Garden.

Watch our 10 min walkthrough of clustering in Lilac
At Lilac, our mission is to help you understand and curate your text data so you can build the best possible LLM apps. We’ve built a new LLM-powered text clustering pipeline that’s more accurate and easy to understand than any clustering approach we’ve seen before. This is our first cloud service that we are launching on Lilac Garden, our new accelerated computation platform.
The problem#
Understanding text datasets poses a unique set of challenges. Unlike images and videos where we immediately can see patterns, text requires a different approach. A common approach to understanding large text datasets is clustering, where semantically similar documents are put in the same bucket, or category. Understanding the relative sizes of the categories allows us to understand how our data is distributed, without having to read every individual document. However document clustering is often tricky to get right, requiring embeddings that capture intent in text, and compute intensive pipelines that can take prohibitively long. The result is a set of cluster IDs that require skimming through individual examples to draw insights.
Our solution#
Our new clustering service aims to solve this problem by simplifying this pipeline to a single API that allows you to hand us a list of documents, and we’ll give you back human-readable cluster names, and categories for clusters, with a highly-optimized, hardware-accelerated cloud pipeline.
We leverage long context embeddings, massively parallel GPU compute, and sophisticated LLMs to generate concise, descriptive titles for each cluster. These clusters play a crucial role in revealing the major segments of your dataset by grouping similar documents together. This approach can dramatically speed up the process of curation, allowing the identification and removal of problematic clusters, sub-sampling large clusters to reduce dataset size, and creating task-specific datasets. Moreover, examining clusters in user-LLM interaction logs sheds light on subtle and potentially hazardous ways in which users engage with your product.
Don’t just take our word for it - check out Lilac’s demo page to see clusters for LLM fine-tuning datasets (OpenOrca, Capybara, UltraChat, Glaive, SlimOrca), LLM eval datasets (MMLU, ARC, Winogrande), user logs (Chatbot Arena), content scraping (HN comments), and more.
Jailbreak clusters#
ChatBot Arena is a website that allows users to interact with and compare chatbot quality. The Arena team has released a subset of redacted user logs, and we discovered that quite a few users test their jailbreaks and prompt injections on the Arena.


Unsurprisingly, another popular theme is users trying to get chatbots to say NSFW things (and they seem to be broadly successful).
Warning
The image below links to explicit content.

Users are also trying to understand the guardrails of the chatbots by poking around controversial topics.

Our cluster breakdown page also supports grouping by custom fields. We can group by the Model column to see what sorts of interactions users have with each model.

We’re excited to see what interesting clusters you find!
Clustering, powered by Lilac Garden#
Lilac users can pip install the latest version on PyPI to run clustering locally. Local clustering works reasonably well up to ~10,000 data points, but it will take a few hours. For users with a GPU and CuML installed, datasets of ~100,000 points should be feasible.
To cluster a dataset is simple, without any hyperparameters.
import lilac as ll
dataset = ll.from_huggingface('LDJnr/Capybara')
dataset.cluster(input='conversation.*.input', use_garden=False)
For datasets larger than 10k rows – or if you’re impatient, like us – Lilac Garden is a remote computation service that powers compute-heavy features like clustering, perplexity scoring, and embedding computation. Lilac Garden clustered our largest datasets of 4 million data points in just an hour. A 10,000 data point dataset would cluster in less than a minute on Garden - 100x faster than local computation!
Lilac Garden fundamentally changed how we interact with data, allowing to use the power of LLMs over entire datasets, without needing to wait and monitor multi-day pipelines.
To join the waitlist, fill out this form.
How we did it#
Historically, clustering as a service has been hard to pull off for several reasons:
Clustering is slow! (A 10k row dataset takes 15 minutes on an M2 Pro Macbook)
Clustering requires the entire dataset to be in RAM. Each new dataset requires fiddling with clustering hyperparameters
The dependencies are fiddly
Finding a good embedding function is hard
Even after you get your clusters, it’s hard to understand what each of the thousands of clusters actually are.
Today, these issues are all solvable, thanks to the work of many other companies and researchers.
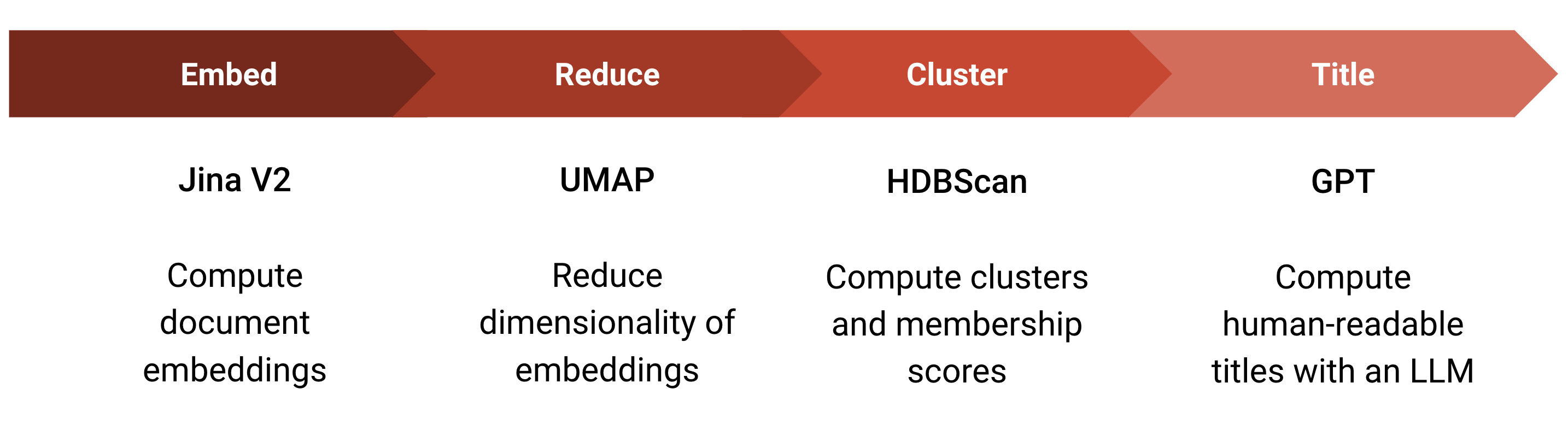
The Lilac Clustering pipeline is a four-step process.
Embed documents with Jina V2, which supports embedding long documents with a single embedding.
Reduce the dimensionality using UMAP, which projects hundreds to thousands of embedding dimensions to a much smaller size, emphasizing scale-free local structure, and feeding well into HDBScan’s cluster detection algorithm.
Compute clusters with HDBScan, enabling clustering without extensive hyperparameter tuning.
Attach human-legible titles to these clusters by asking GPT to title the cluster.
This process, run once, generates fine-grained clusters like “Translating English to Czech” and “Persian-English Translation”. We then repeat the process on the generated titles to create cluster categories, like “Translation”, which categorizes the fine-grained clusters from the first phase of the pipeline.
Thanks to the wizards at NVidia, CuML can accelerate these computations tenfold. Then, we rely on Modal to provide parallel GPUs and a RPC framework to schedule all of these computations. The final step is to put a human-legible label on these clusters by prompt-engineering a command to GPT3.5.
Beyond clusters#
Clustering can give us valuable insights into the shape of our data, or how users are interacting with production systems. However, we can also use the generated clusters to curate data much faster in Lilac:
Drop problematic clusters
Sample across clusters to reduce the size of our dataset
Create a task-specific dataset from a much larger dataset
We’ve uploaded all of the clustered datasets (with cluster titles and cluster IDs) at our HuggingFace page.
Here’s a notebook that demonstrates how to download and filter using our clusters, using Translation clusters in SlimOrca to create a translation-only SlimOrca dataset.
We’re excited to see what you end up doing with the clusters!