Compute or load embeddings#
Indexing data with embeddings allows us to semantically or conceptually search text data. This guide will show you how to compute an embedding over a dataset. For more details on chosing an embedding, see Embeddings.
From the UI#
Important
Embedding indexes can be expensive to compute, however this is a one-time task and enables you to search semantically, or by concept once computed.
We can compute an embedding index with one of two approaches:
1a. From the search box#
From the search box, we can choose a column and an embedding. Then we can click the blue gear icon to compute the index!

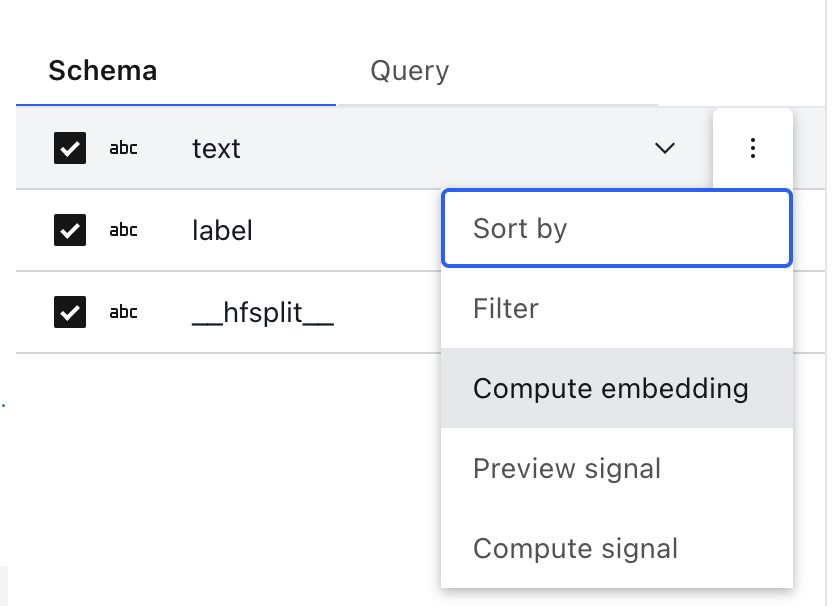
1b. From the schema#
From the schema, we can choose the field’s hamburger menu to click “Compute Embedding”.
From Python#
From Python, we can compute embedding indexes, or load from an external vector store.
Computing embeddings in Lilac#
We can compute embeddings with registered embeddings by using Dataset.compute_embedding. For
more details on chosing an embedding, see Embeddings.
Let’s compute gte-small over the text field:
dataset = ll.get_dataset('local', 'imdb')
dataset.compute_embedding('gte-small', path='text')
Custom embeddings#
Lilac also allows you to register your own embedding function, and/or load your own embeddings from an existing vector store.
We have an accompanying notebook for this workflow.
To do this, we first must register a custom embedding function so that we can compute embeddings on future data.
To demonstrate this, we’ll load an embedding model from HuggingFace SentenceTransformers, and wrap it in a custom Lilac embedding class.
embedding_model = SentenceTransformer('thenlper/gte-small')
def _embed(text):
# Call the gte-small embedding model.
return np.array(embedding_model.encode(text))
# Make an embedding class.
class MyEmbedding(ll.TextEmbeddingSignal):
name = 'my_embedding'
def compute(self, data):
for text in data:
embedding = _embed(text)
# Yield a full chunk embedding. If you want to chunk your text, yield an array here.
yield [ll.chunk_embedding(0, len(text), embedding)]
# Register the embedding under 'my_embedding' so it can be used by Lilac.
ll.register_embedding(MyEmbedding, exists_ok=True)
Once we’ve registered the embedding, we can test it out.
print('Testing the embedding on a single item...')
print(next(MyEmbedding().compute(['This is some text'])))
Output:
[{'__span__': {'start': 0, 'end': 17}, 'embedding': array([-4.39735241e-02, -9.28446930e-03, 4.57611308e-02, -3.19548771e-02,...
We can now compute this embedding from the UI or python, like above.
Loading pre-computed embeddings#
We can also load pre-computed embeddings from an existing vector store by using the
Dataset.load_embeddings method.
Let’s first make a dummy vector store, just a simple dictionary.
items = [
{'id': '0_', 'text': 'This is some fake data'},
{'id': '1_', 'text': 'This is some more fake data'},
{'id': '2_', 'text': 'This is even more fake data'},
{'id': '3_', 'text': 'I love plants'},
]
vector_store = {}
for item in items:
vector_store[item['id']] = _embed(item['text'])
Now let’s load the embeddings. We’ll use a custom lambda function that will read the id from the dataset, and look it up in our vector store.
ds = ll.from_dicts('local', 'load_embedding', items)
# Load the embeddings into Lilac.
def _load_embedding(item):
return vector_store[item['id']]
# Load the embeddings into Lilac.
ds.load_embedding(
load_fn=_load_embedding, index_path='text', embedding='my_embedding', overwrite=True
)
Embeddings are now loaded, and can be used from the UI or from python.
# Select rows using a semantic search.
rows = ds.select_rows(
['text'],
searches=[
ll.SemanticSearch(path='text', query='This is some data', embedding='my_embedding'),
],
)
for row in rows:
print(
row['text'],
row['text.semantic_similarity(embedding=my_embedding,query=This is some data)'][0]['score'],
)
Output:
Computing signal "semantic_similarity" on local/load_embedding:('text',) took 0.016s.
This is some fake data 0.9254916310310364
This is some more fake data 0.9084776043891907
This is even more fake data 0.8841889500617981
I love plants 0.7808101177215576