Load a dataset#
Loading a dataset can be done from the UI or from Python. See lilac.sources for details on
available sources.
From the UI#
Start the webserver#
To start the webserver at a lilac project directory:
lilac start ~/my_project
This will start an empty lilac project under ~/my_project, with an empty lilac.yml and start the
webserver. The configuration for lilac.yml can be found at Config. The lilac.yml file will
stay up to date with interactions from the UI. This can be manually edited, or just changed via the
UI. For more information on peojcts, see Projects.
Load a dataset#
To load a dataset from the UI, click the “Add dataset” button from the “Getting Started” homepage.
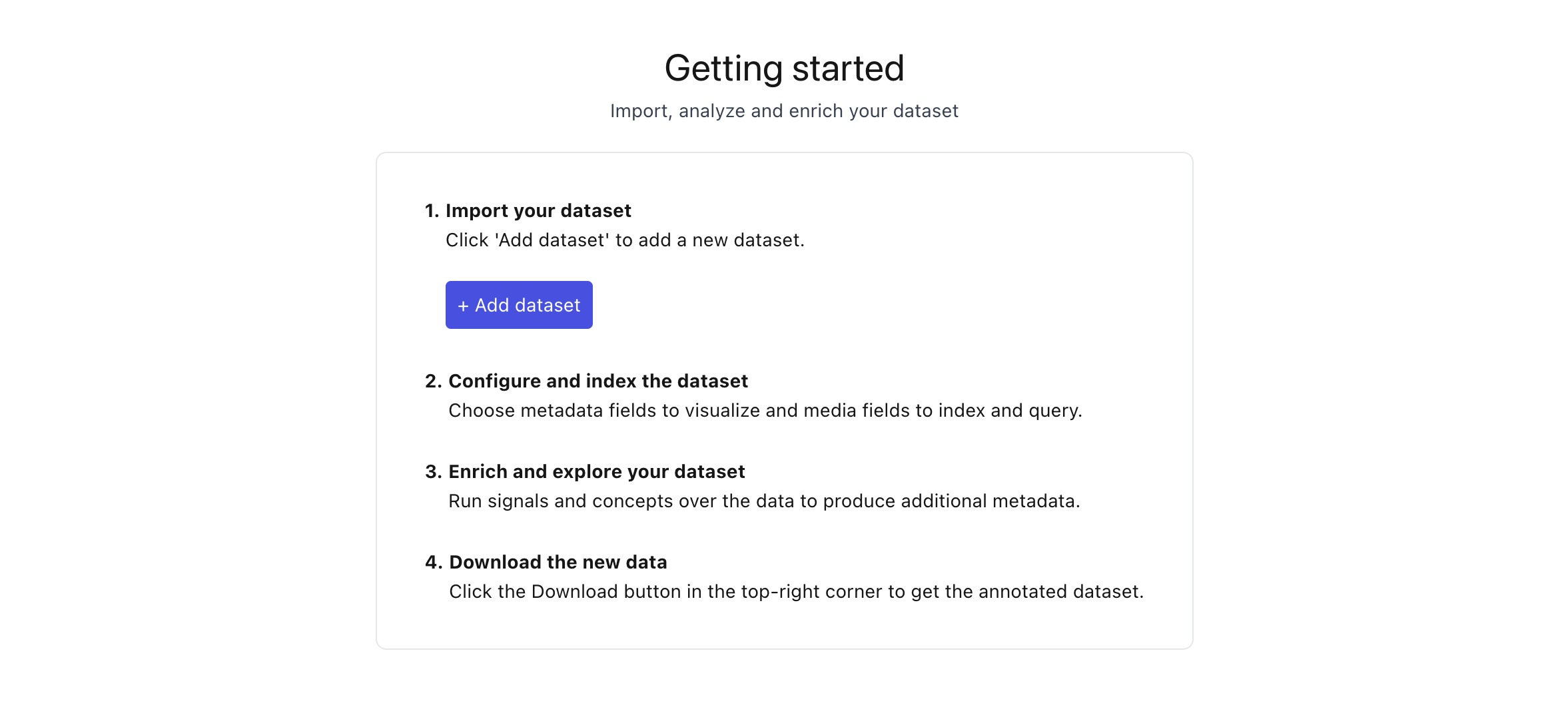
This will open the dataset loader UI:
Step 1: Name your dataset#
namespace: The dataset namespace group. This is useful for organizing dataset into categories, or organizations.name: The name of the dataset within the namespace.
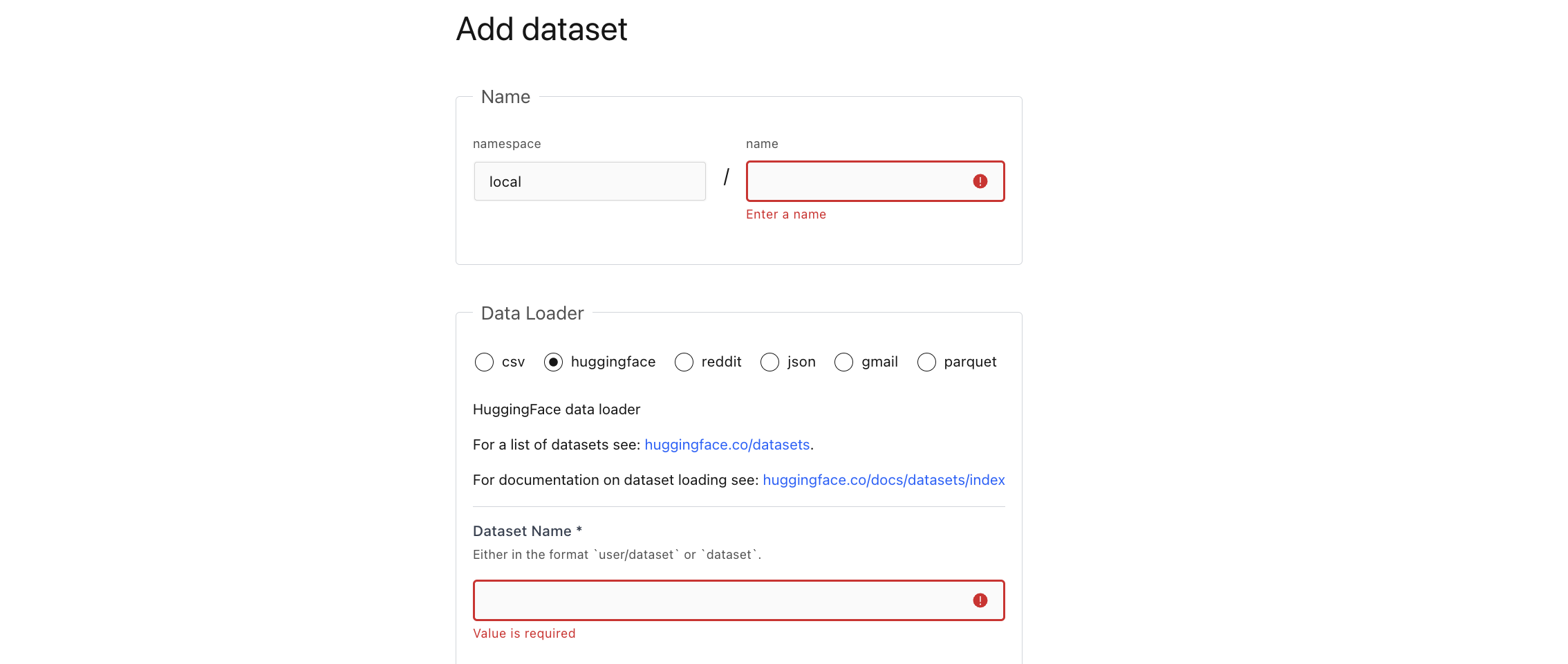
Step 2: Chose a source (data loader)#
csv: Load from CSV files.huggingface: Load from a HuggingFace dataset.json: Load JSON or JSONL files.gmail: Load your emails from gmail. No data is sent to an external server, unless you use a remote embedding. See Embeddings on chosing an embedding.parquet: Load from parquet files.
More details on the available data loaders can be found in lilac.sources.
Don’t see a data loader? File a bug, or send a PR to https://github.com/lilacai/lilac!
Step 3: Load your data!#
After you click “Add”, a task will be created:
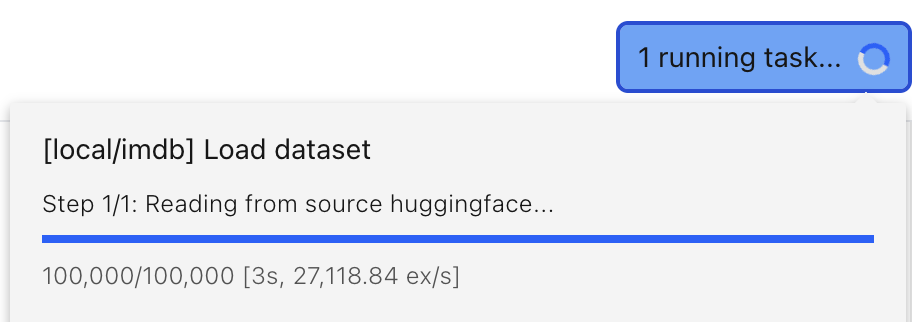
You will be redirected to the dataset view once your data is loaded.
From Python#
Creating a dataset#
You can create a dataset from Python using lilac.create_dataset. Lilac supports variety of data
sources, including CSV, JSON, HuggingFace datasets, Parquet, Pandas and more. See lilac.sources
for details on available sources. All the file based readers support reading from local files, S3
(s3://...), GCS (gs://...) and HTTP(S) URLs.
Before we load any dataset, we should set the project directory which will be used to store all the datasets we import. If not set, it defaults to the current working directory.
import lilac as ll
ll.set_project_dir('~/my_project')
Huggingface#
You can load any HuggingFace dataset by passing the dataset name and config name. We use the HF
dataset loader, which will fetch and cache the dataset in your HF cache dir. Then Lilac will convert
that to our internal format and store it in the Lilac project dir. To read private datasets, either
login via the huggingface-cli or
provide a token to the HuggingFaceSource.
config = ll.DatasetConfig(
namespace='local',
name='glue',
source=ll.HuggingFaceSource(dataset_name='glue', config_name='ax'))
# NOTE: You can pass a `project_dir` to `create_dataset` as the second argument.
dataset = ll.create_dataset(config)
CSV#
The CSV reader can read from local files, S3, GCS and HTTP. If your dataset is sharded, you can use a glob pattern to load multiple files.
url = 'https://storage.googleapis.com/lilac-data/datasets/the_movies_dataset/the_movies_dataset.csv'
config = ll.DatasetConfig(
namespace='local', name='the_movies_dataset', source=ll.CSVSource(filepaths=[url]))
dataset = ll.create_dataset(config)
Parquet#
The parquet reader can read from local files, S3, GCS and HTTP. If your dataset is sharded, you can use a glob pattern to load multiple files.
Sampling
The ParquetSource takes a few optional arguments related to sampling:
sample_size, the number of rows to sample.pseudo_shuffle, defaulting toFalse. WhenFalse, we take an entire pass over the dataset with reservoir sampling. WhenTrue, we read a fraction of rows from the start of each shard, to avoid shard skew, without doing a full pass over the entire dataset. This is useful when your dataset is very large and consists of a large number of shards.pseudo_shuffle_num_shards, the maximum number of shards to read from whenpseudo_shuffleisTrue. Defaults to10.seed, the random seed to use for sampling.
source = ll.ParquetSource(
filepaths=['s3://lilac-public-data/test-*.parquet'],
sample_size=100,
pseudo_shuffle=True)
config = ll.DatasetConfig(namespace='local', name='parquet-test', source=source)
dataset = ll.create_dataset(config)
JSON#
The JSON reader can read from local files, S3, GCS and HTTP. If your dataset is sharded, you can use a glob pattern to load multiple files. The reader supports both JSON and JSONL files.
If the format is JSON, we expect the dataset to be an array of objects:
[
{"id": 1, "text": "hello world"},
{"id": 2, "text": "goodbye world"}
]
If the format is JSONL, we expect each line to be a JSON object:
{"id": 1, "text": "hello world"}
{"id": 2, "text": "goodbye world"}
config = ll.DatasetConfig(
namespace='local',
name='news_headlines',
source=ll.JSONSource(filepaths=[
'https://storage.googleapis.com/lilac-data/datasets/langsmith-finetuning-rag/rag.jsonl'
]))
dataset = ll.create_dataset(config)
Pandas#
df = pd.DataFrame({'test': ['a', 'b', 'c']})
config = ll.DatasetConfig(namespace='local', name='the_movies_dataset2', source=ll.PandasSource(df))
dataset = ll.create_dataset(config)
For details on all the source loaders, see lilac.sources. For details on the dataset config,
see lilac.DatasetConfig.
Loading from lilac.yml#
When you start a webserver, Lilac will automatically create a project for you in the given project
path, with an empty lilac.yml file in the root of the project directory. See
Projects for more information.
import lilac as ll
ll.start_server(project_dir='~/my_lilac')
This will create a project file:
~/my_lilac/lilac.yml
The configuration for lilac.yml can be found at Config. The lilac.yml file will stay up to
date with commands from python, however this file can also be manually edited.
The next time the web server boots up, the lilac.yml file will be read and loaded. Tasks will be
visible from the UI.
Alternatively, you can explicitly load the lilac.yml after editing it without starting the webserver:
ll.load(project_dir='~/my_lilac')
Or from the CLI:
lilac load --project_dir=~/my_lilac