Edit a dataset#
Note
This page goes into the technical details of editing a dataset in Lilac. For a real world example, see the blog post on Curate a coding dataset with Lilac.
Once you bring the data into Lilac, you can start editing it. The main edit operation is creating a
new column via Dataset.map, which takes API inspiration from
HuggingFace’s Dataset.map(). The function being
mapped runs against every row in a table, enhancing that data with new information. For example, we
can call GPT to extract structure from a piece of text, or rewrite a piece of text in a different
style or language.
The benefits of using Lilac’s map include the ability to track lineage information for every
computed column, and the ability to resume computation if the processing fails mid-way. We are also
working on the ability to write to an existing column, undo and redo edits, and see a history of all
the edits made.
Dataset.map#
Dataset.map is the main vehicle for processing data in Lilac.
It is fundamentally a row-oriented operation. As a text-oriented tool, Lilac assumes that text processing (via LLMs, etc.) is more expensive than memory access. It is not like pandas, which optimizes for vectorized numerical computation over rows, columns, or entire dataframes.
Lilac will save your map progress: if the map fails mid-way (e.g. with an exception, or your computer dies), you can resume computation without losing any intermediate results. This is important when the
mapfunction is expensive or slow (e.g. calling GPT to edit data, or calling an expensive embedding model).mapoperates seamlessly over repeated subfields: your map only ever sees a flattened stream of items and Lilac keeps track of the association between each item and its source row.The output of Lilac’s
mapis always written to a new column in the same dataset. We’re working on versioned columns, which will allow you to overwrite the same column while being able to compare/undo the change.While the computation is running, the Lilac UI will show a progress bar. When it completes, the UI will auto-refresh and we can use the new column (see statistics, filter by values, etc).
Example usage#
Let’s start with a simple example where we add a Q: prefix to each question in the dataset. By
default, Lilac reads the entire row and your map function will receive the row as a dictionary.
import lilac as ll
items = [{'question': 'A'}, {'question': 'B'}, {'question': 'C'}]
dataset = ll.from_dicts('local', 'questions', items)
def add_prefix(item):
return 'Q: ' + item['question']
dataset.map(add_prefix, output_path='question_prefixed')
dataset.to_pandas()
question question_prefixed
0 A Q: A
1 B Q: B
2 C Q: C
input_path#
If we want to map over a single field, we can provide input_path. Let’s tell Lilac to only read
the question field. The map will no longer see the entire row, but just a single value from the
field we care about:
def add_prefix(question):
return 'Q: ' + question
dataset.map(add_prefix, input_path='question', output_path='question_prefixed2')
dataset.to_pandas()
question question_prefixed question_prefixed2
0 A Q: A Q: A
1 B Q: B Q: B
2 C Q: C Q: C
input_path is very useful for:
keeping the
mapcode reusable, by decoupling the processing logic from the input schema.transforming repeated fields, by allowing Lilac to handle flattening and unflattening. Your map code will only ever see the flattened stream of fields.
Let’s make a new dataset with a nested list of questions:
items = [
{'questions': ['A', 'B']},
{'questions': ['C']},
{'questions': ['D', 'E']},
]
dataset = ll.from_dicts('local', 'nested_questions', items)
dataset.to_pandas()
questions
0 [A, B]
1 [C]
2 [D, E]
Let’s do the map again, but this time we’ll use input_path=('questions', '*') to tell Lilac to map
over each individual item in the questions list. This is equivalent to mapping over the flattened
list ['A', 'B', 'C', 'D', 'E'].
def add_prefix(question):
return 'Q: ' + question
dataset.map(add_prefix, input_path=('questions', '*'), output_path='questions_prefixed')
dataset.to_pandas()
questions questions_prefixed
0 [A, B] [Q: A, Q: B]
1 [C] [Q: C]
2 [D, E] [Q: D, Q: E]
We can see that the questions_prefixed column is a nested list, with the same nestedness as the
questions column.
output_path#
To test the map function while developing without writing to a new column, we can omit the
output_path argument and print the result of map:
result = dataset.map(add_prefix, input_path='question')
print(list(result))
> ['Q: B', 'Q: C', 'Q: A']
Structured output#
Often our maps will output multiple values for a given item, e.g. when calling GPT to extract
structure from a piece of text. If the output of the map function is a dict, Lilac will
automatically unpack the dict and create nested columns under the output_path. This is useful
when we want to output multiple values for a single input item. For example, we can use a map
function to compute the length of each question, and whether it ends with a question mark:
items = [
{'question': 'How are you today?'},
{'question': 'What kind of food'},
{'question': 'Are you sure?'},
]
dataset = ll.from_dicts('local', 'questions3', items)
def enrich(question):
return {'length': len(question), 'ends_with_?': question[-1] == '?'}
dataset.map(enrich, input_path='question', output_path='metadata')
dataset.to_pandas()
question metadata.length metadata.ends_with_?
0 How are you today? 18 True
1 What kind of food 17 False
2 Are you sure? 13 True
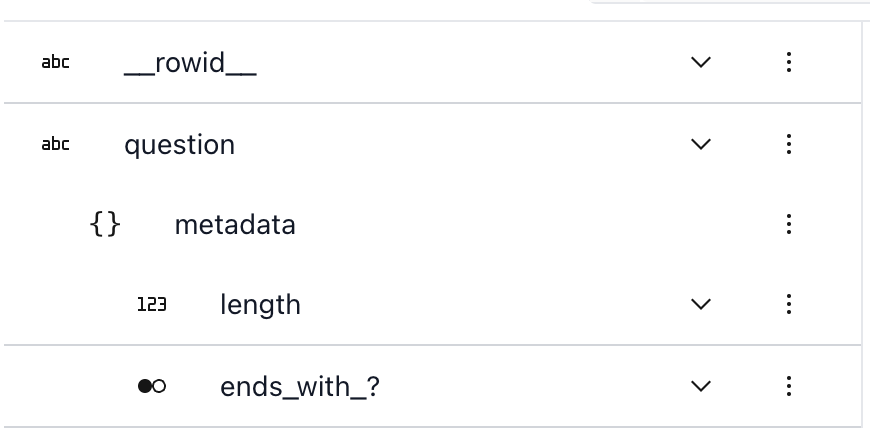
If we start the Lilac web server via ll.start_server() and open the browser, we can see the new
column statistics in the UI and filter by their values:
Batching#
When setting the batch_size kwarg, map will provide your function with a list of batch_size
items at once. You may receive a partial batch at the end of the map, so your function should handle
receiving a batch smaller than batch_size.
You may also set batch_size=-1 in order to receive the entire dataset as a single batch. This may
be useful if some computation requires seeing all rows at once - for example, a duplicate text
detector. This mode will load your entire dataset (or a column of your dataset if input_column is
specified) into memory, so please ensure that you have sufficient memory on your machine.
Filtering and limiting#
To run a preview computation on a few rows and sanity-check your function, run map with limit=5.
To run a computation on a subset of rows, you can pass a set of Filters. For example,
to limit your map to longer strings, you could run
map(fn, filters=[Filter(path='column', op='length_greater', 20)]). Multiple filters are combined
with AND - only rows matching all provided filters will be mapped.
items = [
{'question': 'A', 'source': 'foo'},
{'question': 'B', 'source': 'bar'},
{'question': 'C', 'source': 'bar'}
]
dataset = ll.from_dicts('local', 'questions', items, overwrite=True)
result = dataset.map(
lambda x: x['question'].lower(),
filters=[ll.Filter(path=('source',), op='equals', value='bar')],
limit=1)
print(list(result))
> ['b']
Parallelism#
By default Lilac will run the map on a single thread. To speed up computation, we can provide
execution_type and num_jobs. Executing type can be either threads or processes. Threads are
better for network bound tasks like making requests to an external server, while processes are
better for CPU bound tasks, like running a local LLM.
The number of jobs defaults to the number of physical cores on the machine. However, if our map function is making requests to an external server, we can increase the number of jobs to reach the desired number of requests per second.
def compute(text_batch: list[str])-> list[str]:
# make a single request to an external server.
dataset.map(compute, batch_size=32, input_path='question', execution_type='threads', num_jobs=10)
Assuming a latency of 100ms per request, we can expect to make 10 requests per second with a single job, and 100 requests per second with 10 jobs.
Annotations#
Often our map will extract relevant information that we want to associate with the input text. For
example, when detecting company names, we want to know the location where each company name was
found. We can do this by using lilac.span annotation.
import re
items = [
{'text': 'Company name: Apple Inc.\n Apple Inc is a ...'},
{'text': 'Google LLC is a ... Company name: Google LLC'},
{'text': 'There is no company name here'},
]
dataset = ll.from_dicts('local', 'company', items)
def extract_company(text):
pattern = r'Company name: (.*)?\s'
matches = re.finditer(pattern, text)
return [ll.span(m.span(1)[0], m.span(1)[1]) for m in matches]
dataset.map(extract_company, input_path='text', output_path='company')
dataset.to_pandas()
Lilac will then highlight the spans in the UI when we filter by the company column:
Nested output_path#
If we want to nest the output of a map under an existing column, we can prefix the output_path
with the name of the existing column: :
items = [
{'question': 'How are you today?'},
{'question': 'What kind of food'},
{'question': 'Are you sure?'},
]
dataset = ll.from_dicts('local', 'questions3', items)
def enrich(question):
return {'length': len(question), 'ends_with_?': question[-1] == '?'}
dataset.map(enrich, input_path='question', output_path='question.metadata')
dataset.to_pandas()
question question.metadata.length question.metadata.ends_with_?
0 How are you today? 18 True
1 What kind of food 17 False
2 Are you sure? 13 True