Configure a dataset#
From the UI#
Datasets can be configured during loading, or in the UI by clicking the “Dataset settings” button in the top right corner.

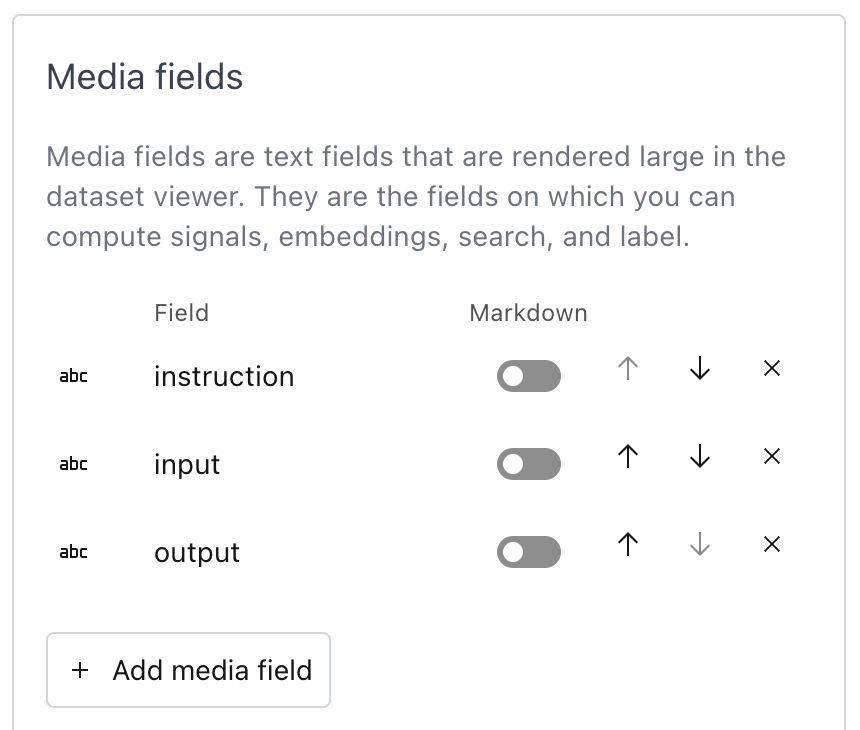
Media fields#
You can elevate certain text fields to media fields, which are rendered large in the dataset viewer. They are the fields on which you can compute signals, embeddings, search, and label. You can also mark each field as markdown to use the markdown renderer. When ingesting data, Lilac will automatically elevate the longest string field as a media field.
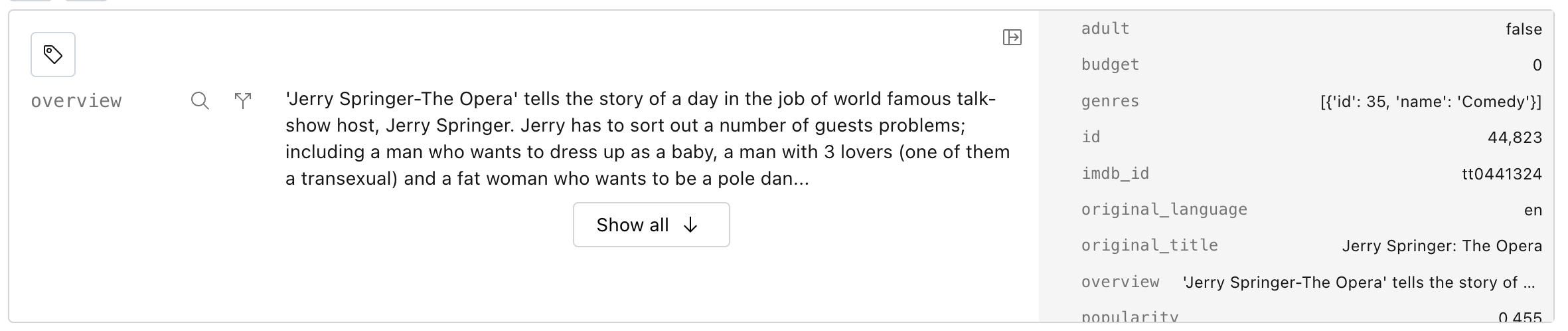
The rest of the fields are metadata fields, which are rendered small on the right hand side of the item.
View type#
Lilac can show the results in an infinite scroll or a paginated single item view. In the paginated single item, you can deep-link to individual data points and use the arrow keys to navigate between items.

| Single item | Infinite scroll |
|---|---|
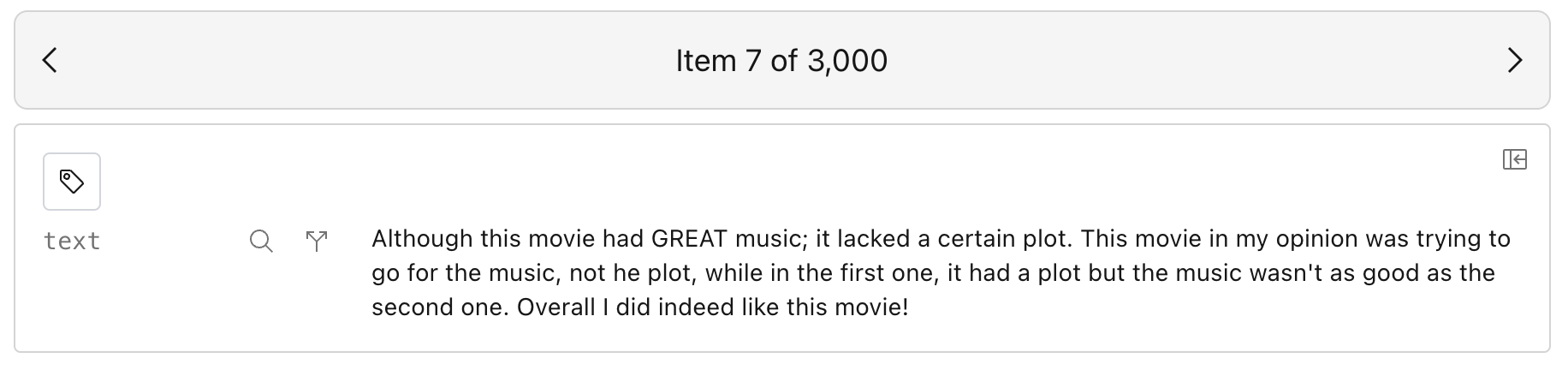 |
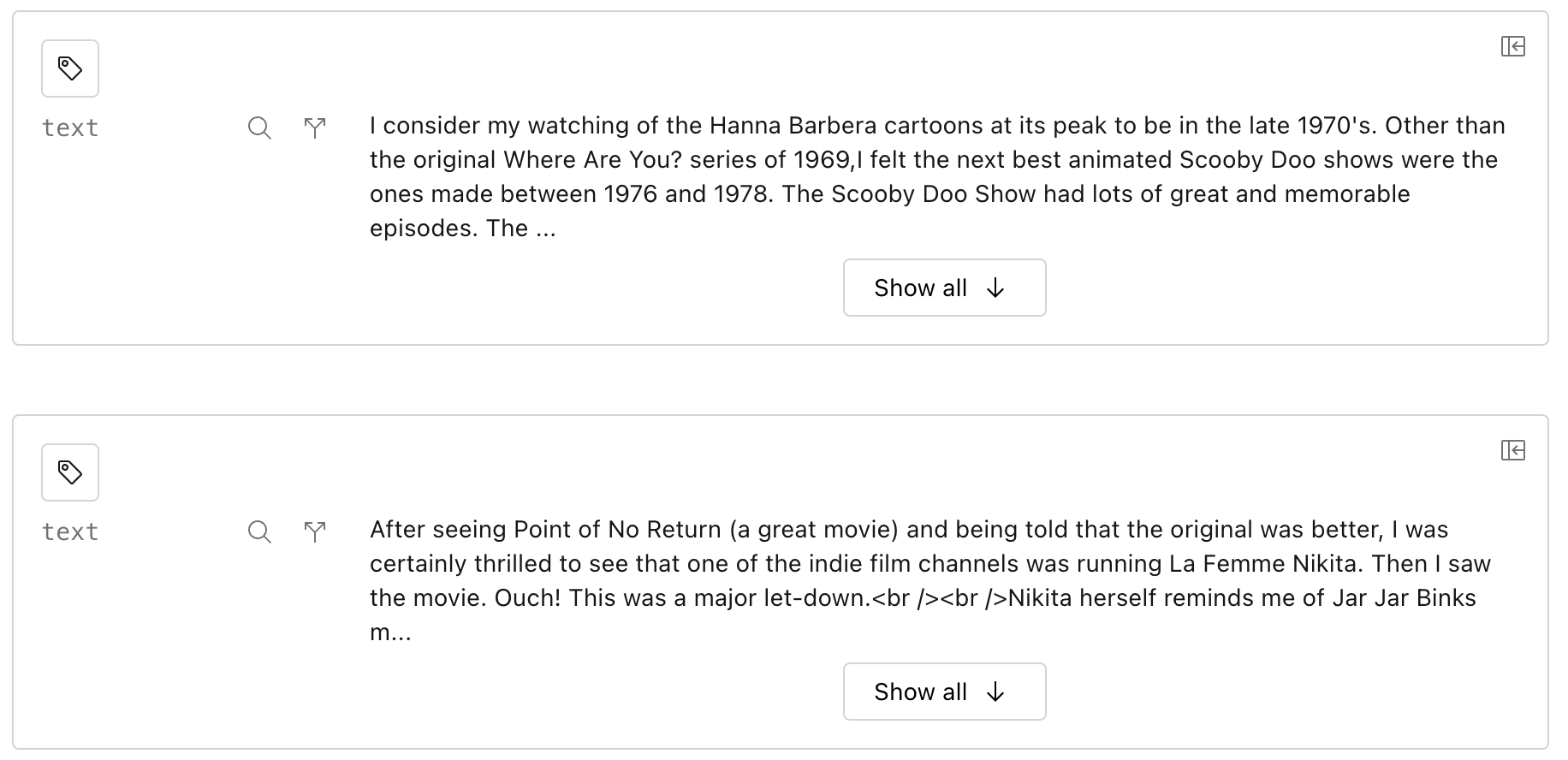 |
Preferred embedding#
You can choose which embedding to use as the default for the current dataset across all users. This embedding will be used to perform semantic and concept search.
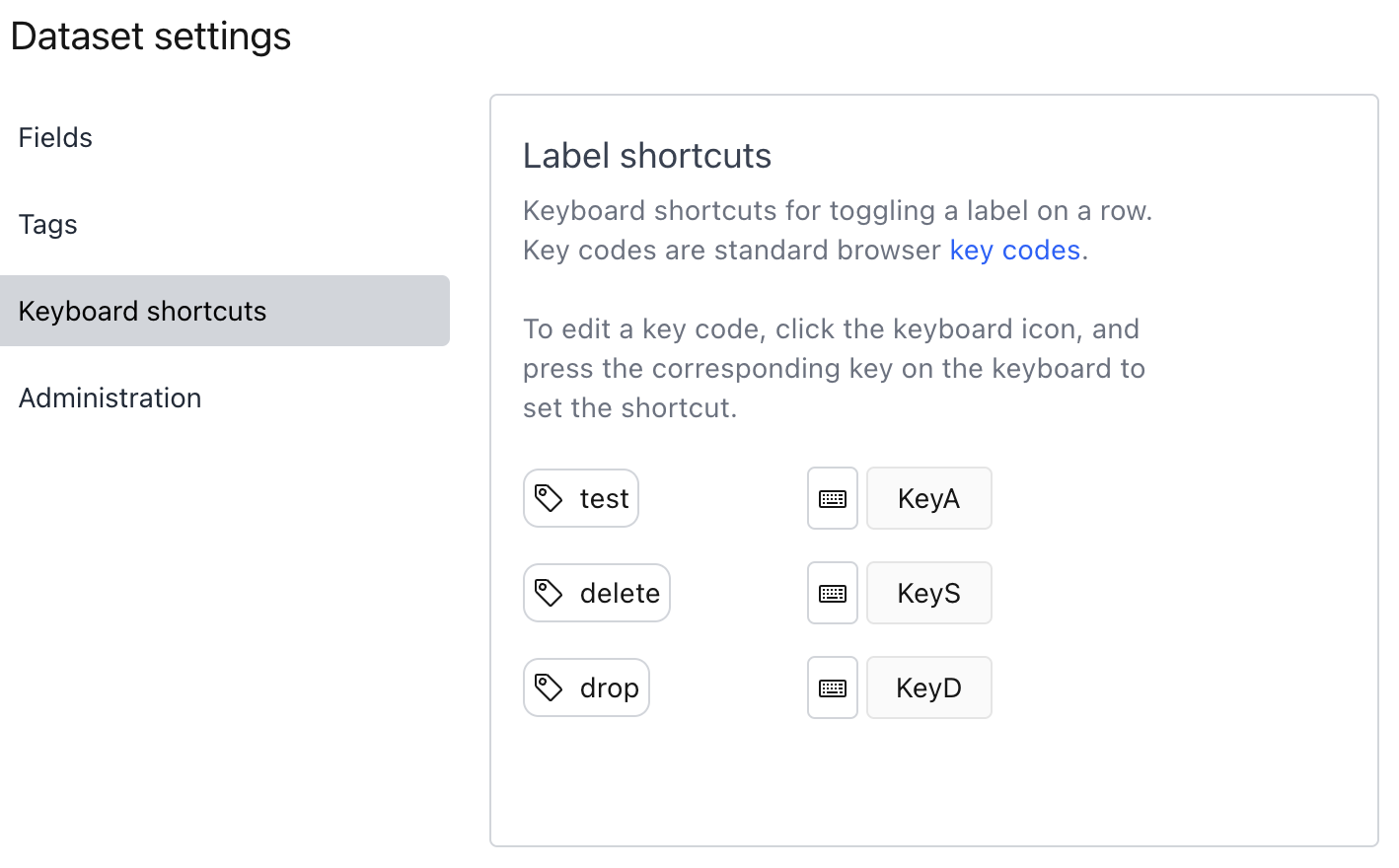
Keyboard shortcuts for fast labeling#
The settings modal also lets you configure keyboard shortcuts to toggle labels on a row to enable fast labeling.
From Python#
You can provide DatasetSettings when you create a new dataset via
DatasetConfig:
import lilac as ll
# 'text' is our media path
settings = ll.DatasetSettings(
ui=ll.DatasetUISettings(
media_paths=[('text',)]),
view_type='single-item'
),
preferred_embedding='gte-small'
)
config = ll.DatasetConfig(
namespace='test_namespace',
name='test_dataset',
source=ll.JSONSource(),
settings=settings,
)
dataset = ll.create_dataset(config)
or update the settings of an existing dataset at any time:
dataset.update_settings(settings)